Code Reviews Are the New Bottleneck
The Game Changed While No One Was Looking
The pull request looked fine. Tests passing. Diff wasn’t large. You scrolled through, nodded at the patterns you recognized, and approved.
Two days later, users started reporting random logouts. No error messages. No pattern anyone could find. Just … sometimes the dashboard would kick them out.
You spent a week chasing it.
The answer, when you finally found it, wasn’t in any single file. It wasn’t a typo or a missed edge case. It was hiding in the space between two systems — each one correct on its own, failing only when they collided under conditions no one had thought to test.
This is a story about that bug. But more than that, it’s a story about why bugs like this are increasingly common, and what to do about it.
What makes code review difficult?
The hardest part of code review isn’t spotting typos or catching obvious errors. It’s holding state in your head.
Every meaningful review requires you to mentally simulate execution: what does this function receive, what does it return, what side effects does it trigger, what assumptions is it making about the state of the world? In a sufficiently sophisticated system — multiple services, async operations, shared databases, external dependencies — this mental simulation becomes nearly impossible for any nontrivial change. You’re not reviewing code so much as you’re reviewing a delta against a system you can only partially hold in working memory.
Most reviewers compensate by narrowing focus. Check the logic in this function. Verify the error handling. Trust that the surrounding system behaves as documented. It’s a reasonable strategy. It’s also how certain categories of bugs slip through — the ones that live in the interaction between components, not in the components themselves.
The “Interaction Bug”
Let’s return to the scenario in our introduction.
The frontend authentication logic was correct: when an API call returned 401, the client would refresh the token and retry. Standard pattern. The backend token rotation was correct too: when a refresh token was used, it was invalidated and a new one issued. This is a security best practice — if someone steals a refresh token, they can’t use it indefinitely.
Both systems were implemented properly. Both had been reviewed. Both would pass any reasonable code inspection.
So, why was it failing?
When the dashboard loads, multiple components mount and make API calls simultaneously. If the user’s access token has expired, all of those calls fail with 401 at roughly the same moment. Each component, following the correct frontend logic, triggers a token refresh.
Now you have three or four refresh requests hitting the backend in parallel, all carrying the same refresh token.
The first one succeeds. The token rotates. The old refresh token is now invalid.
The second request arrives a few milliseconds later, carrying that now-invalid token. From the backend’s perspective, this looks like token theft — someone is trying to reuse a token that’s already been consumed. The security system does exactly what it’s supposed to do: it revokes the entire session and logs the user out.
Neither system is broken. The bug only exists in their interaction, under conditions that don’t appear in any individual code review. You’d have to hold the frontend component lifecycle and the backend security model in your head simultaneously, then trace what happens when they collide under concurrent load.

This is the kind of bug that slips through code review — not because reviewers are careless, but because catching it requires synthesizing knowledge that no single reviewer brings to every PR.
Review is the new bottleneck
There’s a debate happening in software engineering circles right now, and it goes something like this:
One side says AI coding assistants are transformative — that they’ve fundamentally changed what a single developer can accomplish. The other side says the output is unreliable, that you still need experienced humans to catch the mistakes, that AI-generated code creates more problems than it solves.
Both sides are arguing about the wrong thing.
The production question is settled. AI coding assistants are a genuine force multiplier. Not for every task, not without judgment, but as a general rule: a knowledgeable developer using a capable coding assistant produces more functioning code than one working without. This isn’t hype. It’s observable in any team that’s adopted these tools seriously. Features that used to take a week take a day. Boilerplate that used to eat an afternoon gets generated in minutes. The productivity gain isn’t uniform across all tasks, but it’s real and it’s substantial. That genie isn’t going back in the bottle.
But here’s what almost no one is talking about: yes, AI indeed makes mistakes - but AI makes the same categories of mistakes humans make. It misremembers (hallucinates) API signatures. It misunderstands requirements. It writes code that works for the happy path and fails at the edges. It doesn’t hold the full system in its own context window any better than you do in your own head.
You can produce code 20x faster, but you haven’t eliminated errors. You’ve multiplied them.
The bottleneck has shifted. It’s no longer “how fast can we write code?” It’s “how do we review code at a pace that matches how fast we can write it?”
Most teams haven’t caught up to this shift. They’re still optimizing for production speed while their review capacity stays fixed — or worse, shrinks as senior engineers get pulled into more reviews than they can handle thoughtfully.
The inevitable result has a name: AI slop.
AI slop: The predictable failure mode
AI slop isn’t about AI being bad at coding.
It’s about the absence of review at the scale AI produces.
Here’s the question most teams are grappling with, whether they’ve articulated it or not: How do we ship code at this pace safely, responsibly, and with the same quality we believed our code had before AI coding assistants?
That question leads directly to a harder one: How do we review code at a pace that matches how fast we can write it?
When teams stare at that question, they tend to see two choices. Slow down to match human review capacity — which defeats the point of the productivity gain. Or ship without adequate review — which accumulates debt and defects faster than you can pay them down.
Most teams are quietly doing the second while pretending they’re doing the first.
The tells are familiar: PRs that sit in review queues for days because no one has bandwidth. Reviews that consist of a quick scroll and an approval because the reviewer trusts the author. Bugs that make it to production because the code “looked fine” and no one had time to trace through the edge cases.
None of this is new. Teams have struggled with review throughput for as long as code review has existed. AI coding assistants have just taken a chronic problem and made it acute. The volume has changed. The velocity has changed. The gap between code-production capacity and code-review capacity has widened into something that can’t be bridged over with good intentions.
And the failure mode is predictable: code that works until it doesn’t. Systems that seem fine until they encounter load, or concurrent users, or malformed input, or any of the thousand edge cases that didn’t get caught because no one had time to think about them.
This is how AI slop happens. Not because the AI is lazy. Because the humans are overwhelmed.
What rigorous review actually catches
Back to that authentication bug.
Our code review agent flagged the issue during a routine PR review. The finding noted that the frontend’s refresh logic didn’t deduplicate concurrent calls, and that this would interact badly with the backend’s token rotation security model. It traced the execution path: multiple components mount, multiple 401s fire, multiple refresh requests race, and the security system interprets the second request as token theft.
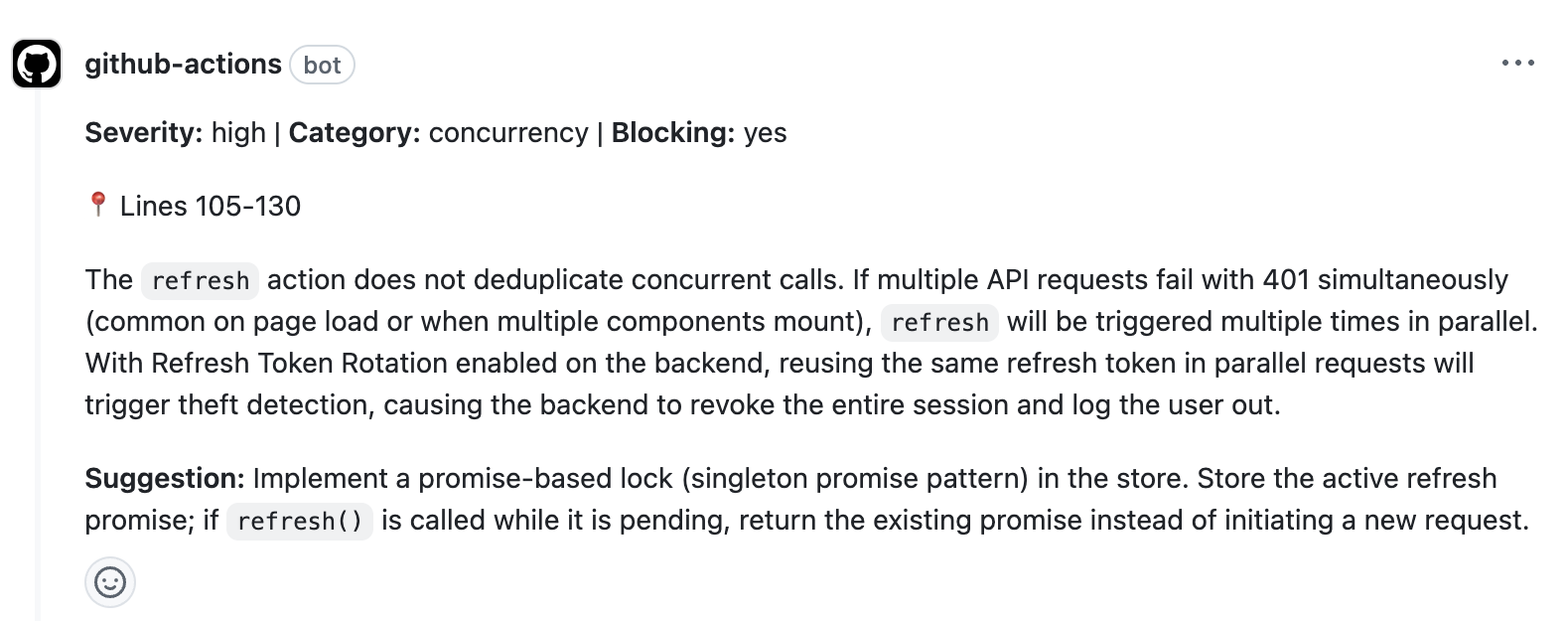
No single file in the PR contained the bug. The bug lived in the interaction between systems — and the review caught it because it was analyzing that interaction, not just the diff.
Examples of common interaction bugs
This wasn’t a fluke. Here’s a sample of what surfaced in a single codebase during development:
A security bypass from order of operations.
User provisioning occurred before invitation validation. If the invitation check failed after the user record was created, the user could simply log in again without an invitation and gain unauthorized access to the tenant. The code worked correctly in the happy path. The security hole only existed in the failure path — and it was a hole that would have been invisible in a linear code review.
A race condition that “shouldn’t” happen inside a transaction.
An approval workflow checked whether a request was still pending, then created an invitation if so. Both operations were inside a transaction. But standard database isolation doesn’t prevent two concurrent transactions from both reading the request as pending. The result: duplicate invitations and corrupted state. Most developers assume transactions protect against races. They don’t — at least not at the isolation levels most applications use.
A performance cliff hiding in plain sight.
A query sorted results by priority using a CASE expression to enforce logical ordering (CRITICAL, HIGH, NORMAL, LOW). The database had an index on the priority column. But because the sort expression didn’t match the index order, Postgres couldn’t use the index for sorting. Every poll operation fetched and sorted all pending rows in memory before applying the limit. The code was correct. It would also fall over under production load.
An availability gap hidden in a convenience feature.
The system allowed overwriting uploaded artifacts by requesting a new upload URL. But requesting the URL immediately reset the file’s status from “Uploaded” to “Pending” — which meant the existing artifact became unavailable for download the moment someone initiated an overwrite. If the new upload was delayed, abandoned, or failed, the original file stayed offline indefinitely. The overwrite feature worked exactly as designed. It just hadn’t accounted for the window between “started replacing” and “finished replacing.”
These aren’t contrived examples. They’re real findings from real development work. And they share a pattern: each one looks correct when you read the code linearly. Catching them requires modeling concurrent execution, understanding database internals, or tracing authorization flows end-to-end.
This is the kind of review that protects codebases from the bugs that matter most — the ones that ship because they’re invisible to a reviewer who’s scanning a diff under time pressure.
The mindset shift
The point of these examples isn’t “look how many bugs exist in code.” Bugs have always existed. The point is that a certain category of bug — the kind that lives in interactions, timing, and system behavior rather than in any single line of code — has become both more common and more consequential.
More common because AI-assisted development moves fast. When you’re shipping features in days instead of weeks, the surface area for interaction bugs grows faster than your mental model of the system can keep up.
More consequential because the systems we’re building are more sophisticated - distributed services, async workflows, multiple frontends hitting shared backends, third-party integrations with their own assumptions and failure modes. The complexity budget has expanded, and the bugs that slip through tend to be the ones that only manifest when that complexity collides with itself.
This isn’t about replacing human judgment. A code review finding isn’t a verdict — it’s an observation that deserves consideration. Sometimes the finding is wrong. Sometimes it’s technically correct but not worth addressing. The value isn’t in blind compliance; it’s in surfacing things that would otherwise go unconsidered.
The developers who will thrive in this environment are the ones who internalize a few shifts:
Treat AI-generated code with the same scrutiny as human-generated code. The machine makes the same categories of mistakes you do. It’s not a source of truth; it’s a very fast pair programmer who doesn’t know what it doesn’t know.
Recognize that review is the new bottleneck. Code production speed is a solved problem. Sustainable velocity — shipping fast without accumulating invisible debt — is the problem that matters now.
Invest in catching problems early. The cost of a bug compounds the longer it lives. A finding caught in PR review is cheap. The same bug caught in production, after users have encountered it and state has been corrupted, is expensive in ways that go beyond engineering time.
Why We built Bop
If you’re building something that matters to you — a product, a platform, a system you’ll be maintaining for years — you already know that shipping fast means nothing if you’re shipping debt.
The promise of AI-assisted development is real. You can move faster than ever before. But speed without quality isn’t velocity; it’s just motion. And the bugs that slip through at speed are exactly the ones that hurt the most later: the race conditions that corrupt data under load, the security gaps that only surface when someone thinks to exploit them, the performance cliffs that stay hidden until you have actual users.
The question isn’t whether you can produce code quickly. The question is whether you can sustain that pace without drowning in the consequences.
We built Bop because we needed it ourselves. We were building a platform, moving fast with AI assistance, and we knew our own review capacity couldn’t keep up with our production capacity. The tool started as a way to get a second set of eyes — a collaborator that could catch the things we’d miss when we were too close to the code or too deep in the weeds to see the system-level interactions.
What we found surprised us. The review quality wasn’t just “good enough as a safety net.” It was catching bugs we wouldn’t have caught — bugs like the ones in this post. Interaction bugs. Timing bugs. The kind of subtle, system-level issues that only surface when you’re holding multiple components in your head at once.
Bop isn’t magic. It won’t catch everything. You’ll disagree with some of its findings (and you should — review is a conversation, not a dictation). But if you’re building something you care about, and you want to move fast without leaving a minefield behind you, it’s worth finding out what a rigorous second opinion would surface in your own codebase.
Get started
Pick one PR — something you’ve already shipped or something in review right now. Run it through Bop. Read what it surfaces, not to obey it blindly, but to see what you weren’t modeling.
That single experiment will tell you whether your review process is keeping pace with your production speed.